売上の正体
売上の正体
売上=訪問数×転換率(コンバージョン)×客単価
ネットでもリアルでも全ての売上はこの公式に集約される
↓
つまり売上を上げるにはこの3つのどれかを改善すれば良い
データ分析フロー
データ分析フロー

1.原データ
2.格納
3.ETL(抽出➡変換・加工➡保存)
4.分析
※1~3番までがデータ分析基盤構築の工程
1.原データ
操作ログや入力ログ、走行ログなどのデータが機械には一時的に保存されている。
(永久ではない)
ログ:コンピュータの世界における、やったことや起こったことの記録
2.格納
原データを取り出して貯めておくところ
構造データ(ある程度整理されているデータ)と
非構造データ(文字、数字の羅列)が存在する
データは、文字ではなく数字で整理し、共通マスタとする
マスタデータ:システムを動かす前から入れておく必要のある基礎となるデータ
トランザクションデータ:システムを動かすことによって蓄積されていくデータ
ex)出退勤管理システムであれば、社員の情報はシステム活用時点で、
すでにシステムに入っているであろうデータがマスタ、
出退勤管理システムが使われることで蓄積されていくデータがトランザクション
3.ETL(抽出➡変換・加工➡保存)
格納してあるデータの状態では、分析のための形にはなっていないので、
①必要データを抽出して、②必要な個所のデータを変換し、データどおしを紐づけ、
③分析に活用できるキレイな状態で保存する(cloud上)
4.分析
データどうしを照らし合わせて、施策、提案を行う
正しく言えば、行いたい分析戦略から逆算して、
現データの取得方法を工夫する必要がある
1~4それぞれに適したツールが存在する
ex)1➡2ツール:トレジャーデータ
たくさんツールを活用することは、扱える人材が希少でありコストも多く発生するが、
扱えるのであれば、速く正確なデータ分析基盤を作り上げることができる
web制作プロセス
web制作プロセス
web制作会社、人材は世の中にたくさん存在するが、レベルはさまざま
(同じページ数でも数万~数千万まで存在)
建設プロセスと似たところがある
・基本的には一つも工程を抜かせない
・後から立ち返せない(ウォーターフォール型という)
調査&企画
・競合調査
・webの理解
↓
コンセプトワーク
・ターゲットを決める(ペルソナ)
・売り方
・見せ方
・コミュニケーションの取り方
↓
サイト設計
・サイト項目の戦略作り
↓
画面設計(フレームワーク)
・画面要素の作成(精度、粒度、要素の広さなど)
↓
デザイン
・サイト設計工程との振り返り
ラフデザイン(色み、画像、2方向、3方向)➡完パケデザイン
※ラフに作成し、クライアントと方向性が正しいか確認
↓
実装設計
制作者(エンジニア)からの視点での落とし込み
↓
コーディング
※エンジニアの工程
↓
テスト
・実機で行う
ポイント
・デザイン➡デザイン工程と比較
・機能➡機能チェック(ECなどは特に)
・ランダム➡ルールなしで、想定外の扱い方をする
(ユーザーは直感でwebを活用するため)
↓
サイト公開
・新規
・旧➡新規 ※大変(データ移行があるため)
↓
保守・運用
・後日追加での変更のためにルールを作っておく
・トラブル時のルールを作っておく
データサイエンス基礎知識
1.データサイエンス
データサイエンスとは:データから有意義なインサイト(物事を見抜く力)を
抽出する学問。本来別々の目的を持つ学問の集合体
➡具体的には、個々の観測データから集合の性質を導き出す技術・学問
➡必要な素養は、主に次の3点
エンジニアリング:コンピュータ技術を駆使してデータを収集・処理する
(プログラミングなど)
データからインサイトを抽出
ビジネス:データ分析の結果をビジネス課題の解決、意思決定に役立たせること
2.機械学習
人工知能➡ルールベース:マニュアルを入れ、その決まりごとに従って判断する
➡機械学習:データとその正解を入れ、機械が法則を見つけ出し予測を立てる
ルールベース(従来手法)
メリット:人間の理論によって分析を行うため、理解されやすい
デメリット:時間と業務量がかかる
メリット:短期間で高精度な分析ができる
デメリット:ブラックボックス度が高い(根拠が見い出せないことが多い)
Q。なぜ機械学習が可能になったのか?
A.必要な要素である。ビッグデータ(材料)、ハードウェア性能の向上(燃料)、
アリゴリズムの改善(手法)
機械学習には現在3種類ある
コンピュータに特徴量と正解を全てに与え、予測を立て、未知データの予測値を算出
➡人間が特徴量と正解を認識している
コンピュータに特徴量と正解を全てに与えず、勝手にデータの関係性を導き出し、
未知データの予測値を算出
➡人間が特徴量と正解を認識できていないので、与えられない
コンピュータに特徴量と正解を一部に与える
➡人間が特徴量と正解を一部認識できており、目的(ゴール)のためのプロセスに点数
などの評価を与えて、精度を高める
※特徴量…データの特徴を定量的(数値など)に表す
3.教師あり学習モデル構築の基本フロー
①データの読み込み
↓
②データの理解:データの特徴を観察
↓
③モデルの選択:問題ごとに適切なモデル(ツール)を選択
↓
④特徴量の設計:生データを加工する
↓
⑤モデルの学習
↓
⑥精度評価:制度が十分でない場合、③、④の再構築を行う
精度の決め手は、データの質と特徴量の設計(上記④)
その特徴量設計は最も労力を費やされ、最も分析の精度を左右する工程
➡そこで、特徴量をデータから自動的に抽出できるディープラーニングが登場
ディープラーニング:ニューラルネットワークとコンピュータ技術の組み合わせ
企画構築のフロー
企画構築のフロー
①顧客を創造すること
↓
②自分が必要だと感じていること、困っていること、あったらいいなと思うことを
イメージしてみる
↓
③「三方良し」を意識(売り手、買い手、世間)
↓
④そのための調査を行う
↓
⑤最後はシンプルに!
事業の目的を一行で書いてみる
その目的から外れるものは余分なものと考える
↓
⑥その具体性は時間軸の長さによる
↓
⑦人に伝える
伝え方は、
1.結論から入って理由を伝える
2.ストーリーから入って結論につなげる
※資料は絵、図、数字などイメージしやすいもので示す
ビジネスモデル2.0図鑑
1.経営資源の4要素
ヒト:新たな企業や業界、人を巻き込む
モノ:物の本質的な価値を再定義する
カネ:これまでお金にならなかった、新たなお金の流れをつくる
これらのうち1つ(あるいは複数)を根本から刷新することで、新しい仕組みが生まれてくる。
2.生き残るビジネスモデル
重要ワードは3点
・創造性➡逆説の構造
・社会性➡八方よし
・経済性➡儲けの仕組み
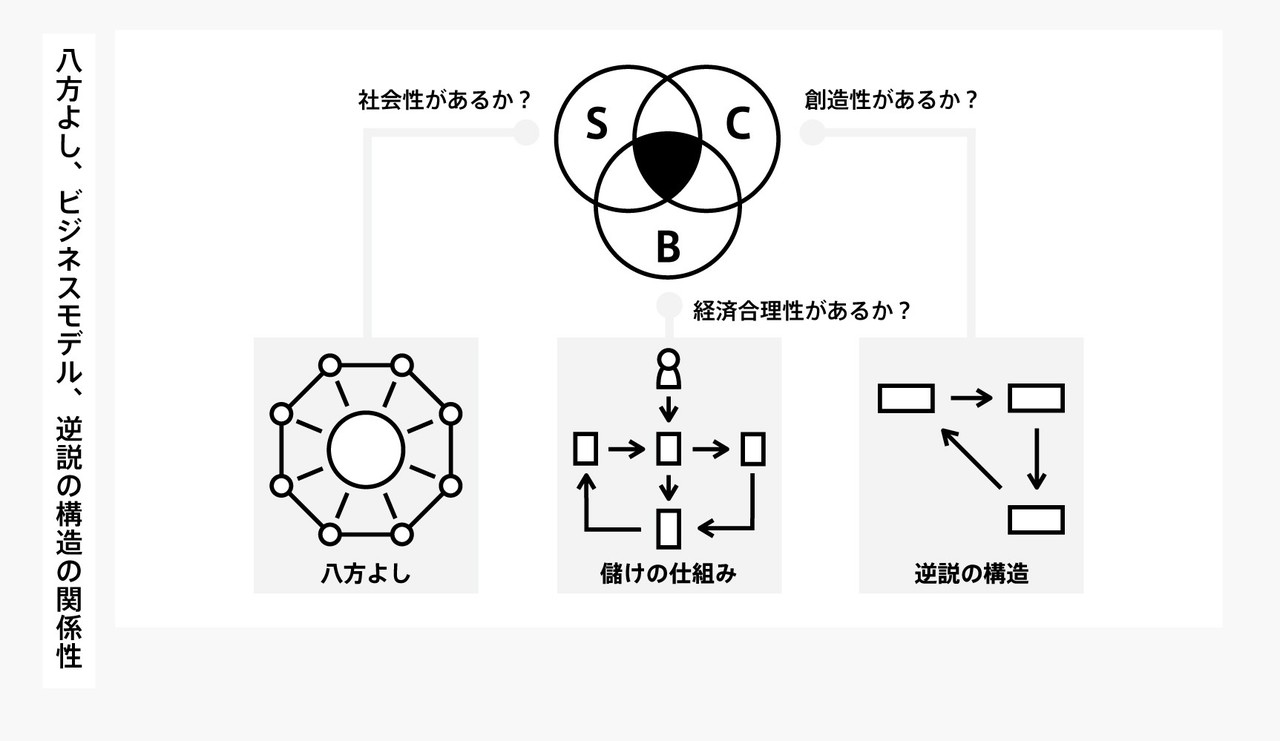
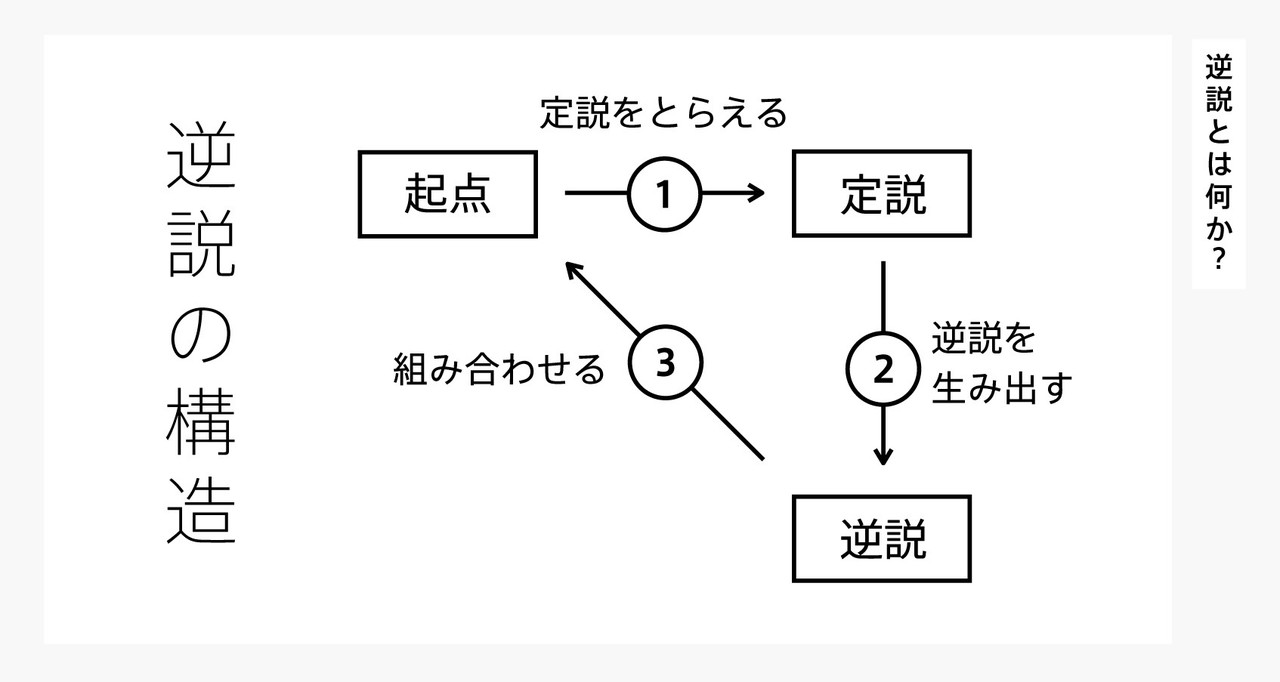
・逆説の構造
➡創造性
①起点(事業領域)から定説(現状の当たり前のこと)をとらえる
②定説から逆説(異なる発想)を生み出す
※逆説は一つとは限らない
③逆説を起点と組み合わせる
↓
起点って普通、定説だよね
でも対象は逆で逆説なんだ
ポイント
・逆説が非常識的であるほど、成り立たせることは高度な仕組みが必要で、
成り立った時にはより価値がある
・定説は移り変わっていく。なので時代の変化に合わせて何度も定説と逆説を
繰り返し変化させていく必要がある
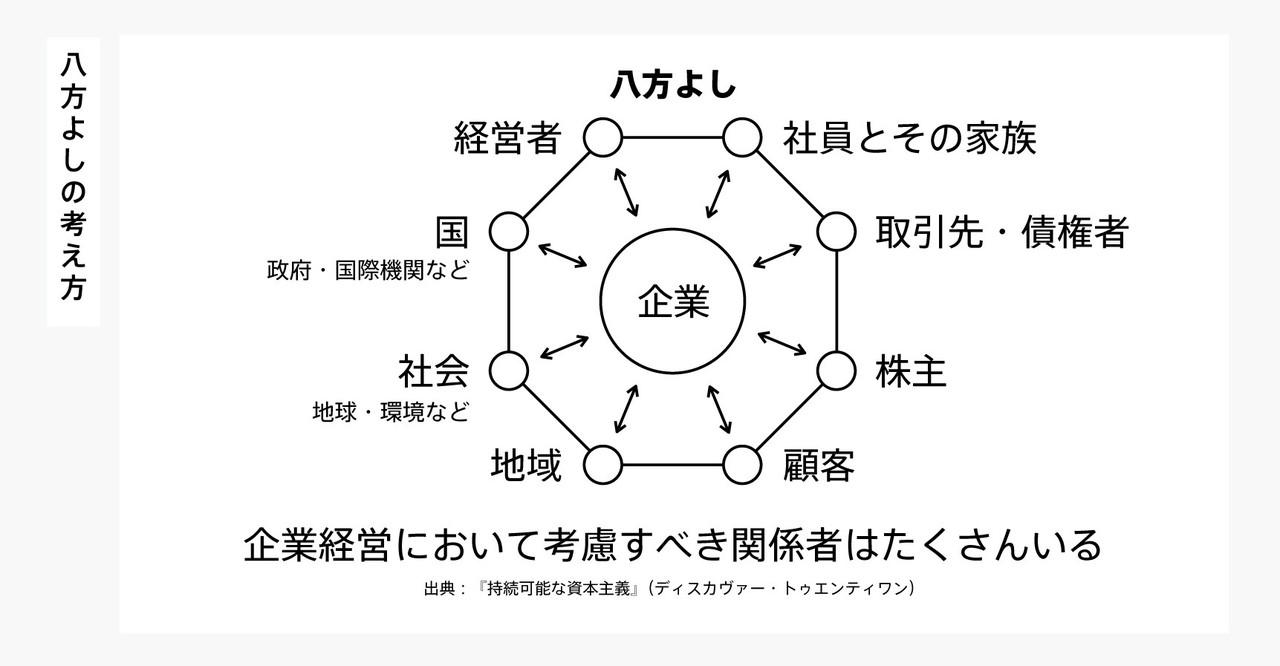
・八方よし
➡社会性
創造性や収益の仕組みが素晴らしくても、社会性が欠落していては、長続きはしない
ex)仕組みは画期的で収益が出ているが、環境汚染につながっているモデル
・儲けの仕組み
➡経済性
企業活動は、純資産と負債で集めた資金(B/S右側)を、資産(B/S左側)に変換することで、顧客に価値を提供し、結果的に利益を生む構造。つまりビジネスの根幹は資産への変換にある。
3.なぜ、経済性(収益)だけでなく創造性、社会性が必要なのか
①創造性
Q.資本→資産への変換の中で創造性はどこに入るのか?
A.無形資産
➡ブランドや信用、人材、アイディア、ノウハウなど(別名:のれん)
・ B/Sで記載されない資産
・無形資産はお金だけでは得られない
↓
「無形資産」こそ企業価値の源泉
②社会性
Q.資本→資産への変換の中で社会性の役割は?
A.まだ財務諸表に表れていない将来的なリスクにアプローチすること
➡リスク情報、サステナビリティの課題など
↓
非財務を無形資産へ
参考:ビジネス2.0図鑑